FOMO is a TinyML neural network for real-time object detection

[ad_1]
This article is part of our coverage of the latest in AI research.
A new machine learning technique developed by researchers at Edge Impulse, a platform for creating ML models for the edge, makes it possible to run real-time object detection on devices with very small computation and memory capacity. Called Faster Objects, More Objects (FOMO), the new deep learning architecture can unlock new computer vision applications.
Most object-detection deep learning models have memory and computation requirements that are beyond the capacity of small processors. FOMO, on the other hand, only requires several hundred kilobytes of memory, which makes it a great technique for TinyML, a subfield of machine learning focused on running ML models on microcontrollers and other memory-constrained devices that have limited or no internet connectivity.
Image classification vs object detection
TinyML has made great progress in image classification, where the machine learning model must only predict the presence of a certain type of object in an image. On the other hand, object detection requires the model to identify more than object as well as the bounding box of each instance.
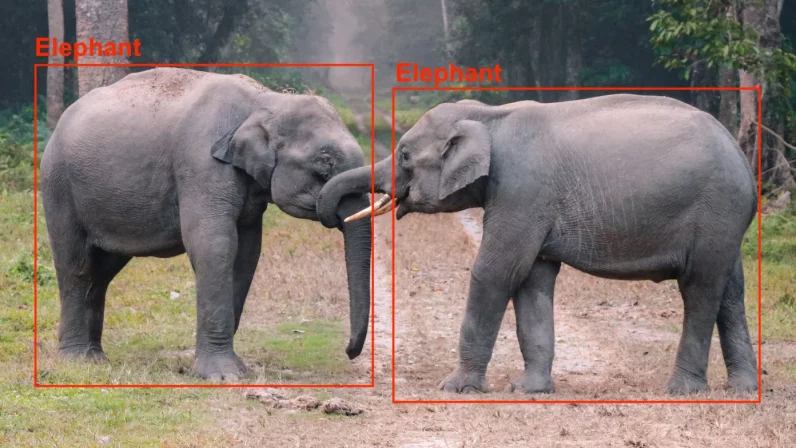
Object detection models are much more complex than image classification networks and require more memory.
“We added computer vision support to Edge Impulse back in 2020, and we’ve seen a tremendous pickup of applications (40 percent of our projects are computer vision applications),” Jan Jongboom, CTO at Edge Impulse, told TechTalks. “But with the current state-of-the-art models you could only do image classification on microcontrollers.”
Image classification is very useful for many applications. For example, a security camera can use TinyML image classification to determine whether there’s a person in the frame or not. However, much more can be done.
“It was a big nuisance that you’re limited to these very basic classification tasks. There’s a lot of value in seeing ‘there are three people here’ or ‘this label is in the top left corner,’ e.g., counting things is one of the biggest asks we see in the market today,” Jongboom says.
Earlier object detection ML models had to process the input image several times to locate the objects, which made them slow and computationally expensive. More recent models such as YOLO (You Only Look Once) use single-shot detection to provide near real-time object detection. But their memory requirements are still large. Even models designed for edge applications are hard to run on small devices.
“YOLOv5 or MobileNet SSD are just insanely large networks that never will fit on MCU and barely fit on Raspberry Pi–class devices,” Jongboom says.
Moreover, these models are bad at detecting small objects and they need a lot of data. For example, YOLOv5 recommends more than 10,000 training instances per object class.
The idea behind FOMO is that not all object-detection applications require the high-precision output that state-of-the-art deep learning models provide. By finding the right tradeoff between accuracy, speed, and memory, you can shrink your deep learning models to very small sizes while keeping them useful.
Instead of detecting bounding boxes, FOMO predicts the object’s center. This is because many object detection applications are just interested in the location of objects in the frame and not their sizes. Detecting centroids is much more compute-efficient than bounding box prediction and requires less data.

Redefining object detection deep learning architectures
FOMO also applies a major structural change to traditional deep learning architectures.
Single-shot object detectors are composed of a set of convolutional layers that extract features and several fully-connected layers that predict the bounding box. The convolution layers extract visual features in a hierarchical way. The first layer detects simple things such as lines and edges in different directions. Each convolutional layer is usually coupled with a pooling layer, which reduces the size of the layer’s output and keeps the most prominent features in each area.
The pooling layer’s output is then fed to the next convolutional layer, which extracts higher-level features, such as corners, arcs, and circles. As more convolutional and pooling layers are added, the feature maps zoom out and can detect complicated things such as faces and objects.

Finally, the fully connected layers flatten the output of the final convolution layer and try to predict the class and bounding box of objects.
FOMO removes the fully connected layers and the last few convolution layers. This turns the output of the neural network into a sized-down version of the image, with each output value representing a small patch of the input image. The network is then trained on a special loss function so that each output unit predicts the class probabilities for the corresponding patch in the input image. The output effectively becomes a heatmap for object types.

There are several key benefits to this approach. First, FOMO is compatible with existing architectures. For example, FOMO can be applied to MobileNetV2, a popular deep learning model for image classification on edge devices.
Also, by considerably reducing the size of the neural network, FOMO lowers the memory and compute requirements of object detection models. According to Edge Impulse, it is 30 times faster than MobileNet SSD while it can run on devices that have less than 200 kilobytes of RAM.
For example, the following video shows a FOMO neural network detecting objects at 30 frames per second on an Arduino Nicla Vision with a little over 200 kilobytes of memory. On a Raspberry Pi 4, FOMO can detect objects at 60fps as opposed to the 2fps performance of MobileNet SSD.
Jongboom told me that FOMO was inspired by work that Mat Kelcey, Principal Engineer at Edge Impulse, did around neural network architecture for counting bees.
“Traditional object detection algorithms (YOLOv5, MobileNet SSD) are bad at this type of problem (similar-sized objects, lots of very small objects) so he designed a custom architecture that optimizes for these problems,” he said.
The granularity of FOMO’s output can be configured based on the application and can detect many instances of objects in a single image.

Limits of FOMO
The benefits of FOMO do not come without tradeoffs. It works best when objects are of the same size. It’s like a grid of equally sized squares, each of which detects one object. Therefore, if there is one very large object in the foreground and many small objects in the background, it will not work so well.
Also, when objects are too close to each other or overlapping, they will occupy the same grid square, which reduces the accuracy of the object detector (see video below). You can overcome this limit to an extent by reducing FOMO’s cell size or increasing the image resolution.
FOMO is especially useful when the camera is in a fixed location, for example scanning objects on a conveyor belt or counting cars in a parking lot.
The Edge Impulse team plans to expand on their work in the future, including making the model even smaller, under 100 kilobytes and making it better at transfer learning.
This article was originally written by Ben Dickson and published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
[ad_2]
Source link